Agir efficacement est la clé du succès
Les organisations d’entraide, les donateurs et les bailleurs de fonds institutionnels visent ensemble à faire une différence pour une bonne cause. L’action orientée vers l’impact peut être intégrée en six étapes dans les processus de travail existants. Le Zewo Impact Tool soutient les organisations d’entraide dans cette démarche.
Dès maintenant avec de nouvelles fonctions d’exportation et des tutoriels vidéo pratiques !
En six étapes vers l’efficacité
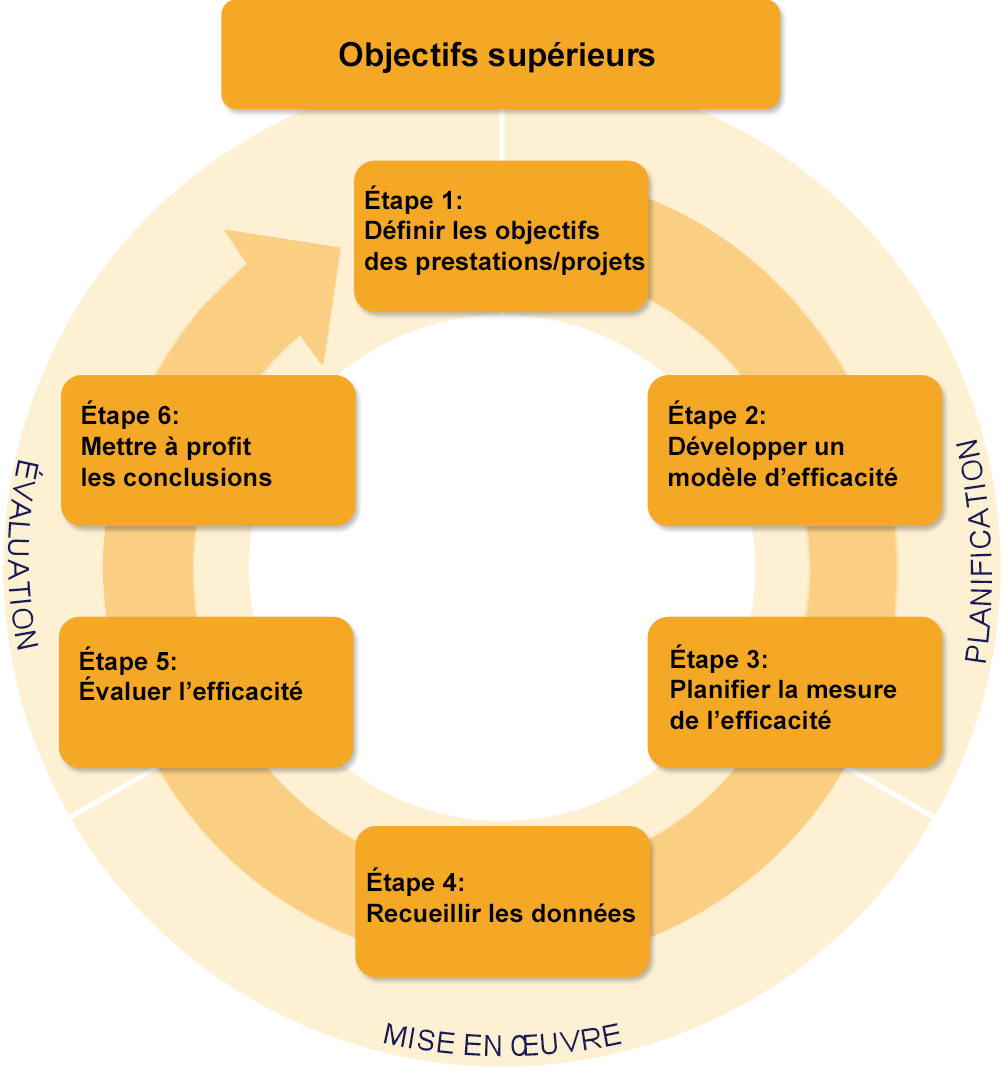
L’orientation vers l’impact commence par une bonne planification de l’intervention. Les organisations qui visent à atteindre les résultats souhaités suivent de près l’évolution de leur travail. Les données de suivi forment la base pour évaluer les effets et tirer des conclusions pour l’avenir.
Le Zewo Impact Tool

Le Zewo Impact Tool aide les organisations d’entraide à développer rapidement un modèle d’impact, à formuler des objectifs mesurables et à suivre les progrès de leur travail.
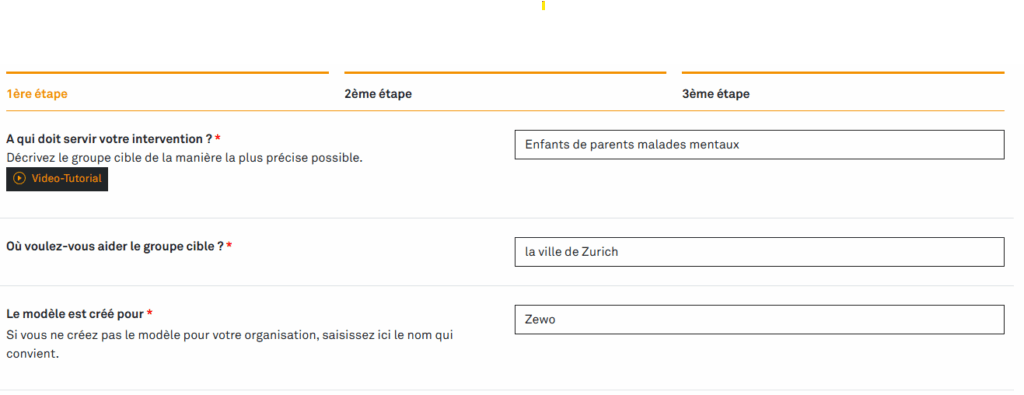
Étape 1 : définir les objectifs
Les organisations d’entraide cherchent à améliorer la situation pour leur groupe cible par leurs interventions. Elles sont au courant de la situation actuelle, connaissent les besoins et ont une idée de ce qui devrait changer et pour qui. Pour aider, elles planifient des projets ou disposent déjà de services.
Voici comment le Zewo Impact Tool vous aide :
Guidé par des écrans de saisie pratiques, vous décrivez comment un service ou un projet spécifique devrait aider votre groupe cible. Vos données sont protégées. C’est vous qui décidez qui a accès à votre analyse.
Étape 2 : élaborer un modèle d’impact
Un modèle d’impact montre les effets visés par une activité particulière et la manière dont ils doivent être atteints. Il clarifie ce qui doit changer, ce qui devrait être atteint et par quel moyen, et qui fait quoi pour cela. Le modèle d’impact donne aux organisations un cadre permettant de suivre et d’évaluer si leurs interventions ont été efficaces et utiles. Il les aide à voir si la théorie du changement sur laquelle repose le modèle, avec ses hypothèses sur les causes et les effets, était appropriée.
Voici comment le Zewo Impact Tool vous aide :
Répondez à quelques questions pour décrire ce que votre organisation fait ou prévoit de faire et les effets qu’elle espère en tirer. Les questions évoluent de manière dynamique. Cela signifie que vos réponses produiront les questions suivantes. Des menus de sélection et des exemples simplifient vos saisies.
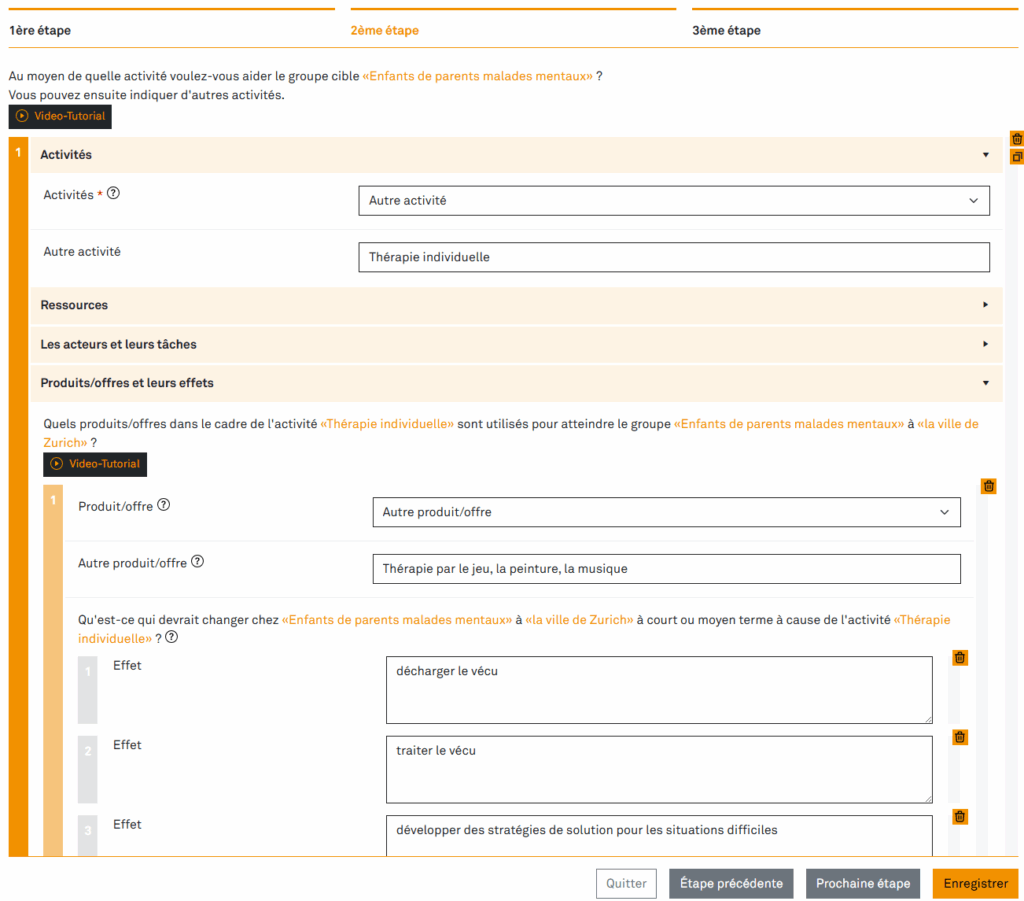
Créez ensuite le modèle d’impact en un seul clic. Vous pouvez le compléter ou l’affiner à tout moment. Téléchargez ensuite le modèle final pour l’éditer en tant que document texte.
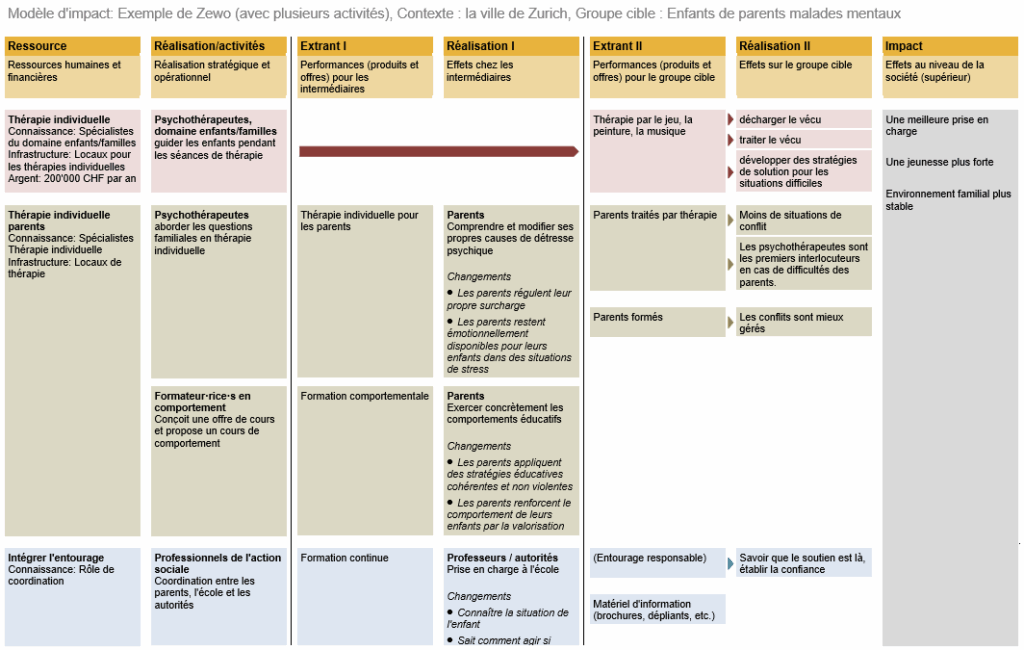
Étape 3 : planifier la mesure de l’efficacité
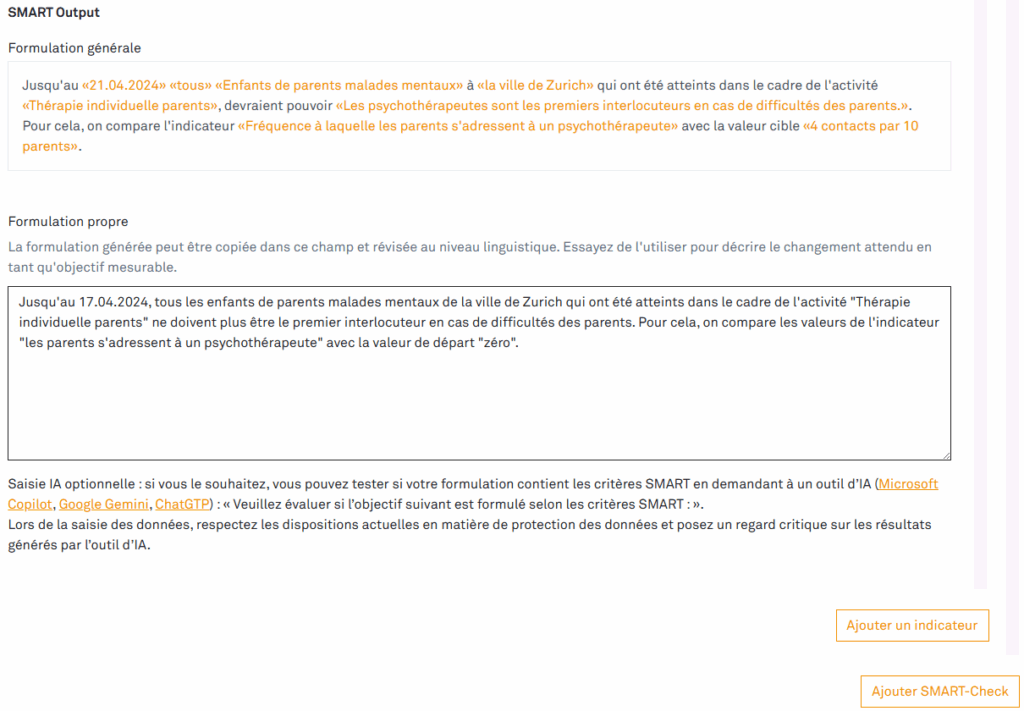
Mais comment les organisations d’entraide peuvent-elles savoir si leurs interventions produisent les effets souhaités ? La réponse à cette question est la clé du succès. Pour évaluer les progrès, les organisations d’entraide doivent préciser leurs objectifs à l’aide d’indicateurs mesurables. De tels indicateurs répondent aux critères SMART suivants :
- Specific : l’indicateur doit être univoque et clair.
- Measurable : l’indicateur doit être mesurable avec un effort raisonnable.
- Achievable : la valeur cible fixée par l’indicateur doit être réalisable.
- Relevant: l’information que revêt l’indicateur doit être un repère significatif pour le projet
- Time-bound: ‘lindicateur doit indiquer d’ici à quand l’objectif devrait être atteint.
Quelle: European Commission, PCM Guidelines
Voici comment le Zewo Impact Tool vous aide :
L’outil vous pose les questions pour définir des indicateurs et des effets mesurables pour votre modèle d’impact. En fonction de vos réponses, il vous propose un texte pour un objectif mesurable. Ajustez-le si nécessaire. Puis, faites le SMART-Check – même si c’est juste pour le plaisir. Il vous aide à juger si votre objectif répond aux critères SMART et vous donne des pistes d’amélioration.
Étape 4 : collecter les données de suivi
Avant de réaliser un projet ou une activité, les organisations d’entraide doivent savoir comment collecter et enregistrer les données afin de suivre les progrès accomplis par rapport aux effets visés. Un bon plan de suivi de projet facilite énormément le travail.
Voici comment le Zewo Impact Tool vous aide :

Vous avez déjà défini les éléments clés de la collecte de données lors du SMART-Check. Par exemple, vous avez défini les étapes de mesure et décidé de ce que vous voulez comparer. Créez maintenant le tableau de progrès en un seul clic. Il indique quelles données vous devez collecter et à quel moment.
Étape 5 : évaluer l’efficacité
Pour évaluer les effets prévus, les données collectées doivent être analysées. Si une organisation a mis en place plusieurs étapes de mesure, elle peut vérifier systématiquement si elle est sur la bonne voie. Si nécessaire, elle peut prendre des mesures de pilotage pour adapter la mise en œuvre à un stade précoce. La possibilité de comparer le groupe cible avec un groupe de référence facilite la réflexion sur d’éventuels facteurs alternatifs expliquant les effets mesurés.
Voici comment le Zewo Impact Tool vous aide :

Téléchargez le tableau de progrès en tant que fichier Word pour y noter les valeurs mesurées. Évaluez vos activités en comparant les valeurs réelles avec les valeurs planifiées. Y a-t-il des écarts significatifs ? Si oui, prenez des mesures de pilotage et notez-les dans le champ correspondant du tableau. De cette manière, vous rapportez des effets et démontrez que votre organisation suit une approche adaptative.
Étape 6 : utiliser les constats
Une action orientée vers l’efficacité signifie davantage que collecter des données et en mesurer les effets. Il s’agit d’interpréter les données et d’en tirer des conclusions. Le suivi ne permet pas seulement d’évaluer les progrès réalisés par rapport aux effets prévus, de suivre les écarts et d’en identifier les causes possibles. Il sert également à réfléchir de manière critique à la conception d’une intervention et au modèle d’impact avec ses hypothèses de cause et d’effet ainsi qu’à examiner la mise en œuvre d’un projet ou d’un service. Il s’agit d’apprendre, de tirer des leçons et de faire des ajustements pour l’avenir : Qu’est-ce qui doit être modifié ou remplacé ? Quelles ressources peuvent être déplacées ou réaffectées ? Les conclusions tirées du suivi peuvent également être utilisées pour planifier la phase suivante ou les interventions futures. Des résultats de suivi pertinents facilitent l’analyse du contexte, l’identification des parties impliquées et l’analyse des problèmes.
Voici comment le Zewo Impact Tool vous aide :
Incluez le tableau d’avancement complété dans votre rapport. Sur cette base, décrivez les résultats dans la partie narrative du rapport et expliquez les décisions de pilotage ainsi que leurs effets sur la suite de l’intervention. De cette manière, vous exploitez au mieux votre tableau de progrès et vous vous assurez que votre intervention et votre rapport sont axés sur l’impact.
Testez maintenant le Zewo Impact Tool
Infobox Zewo Impact Tool (ZIT)- tout en un coup d’œil :
| Version light : gratuite pour tous 1 utilisateur:trice, 1 analyse d’impact, 1 activité, exportation du modèle d’impact Version complète : gratuit pour les organisations d’entraide titulaires du label de qualité Zewo, 180 CHF /an pour tous les autres 5 activités par analyse d’impact, nombre illimité d’analyses d’impact, analyse d’impact divisible à l’intérieur et à l’extérieur de l’organisation, exportation du modèle d’impact et tableau de progression Langues : français, allemand, anglais Enregistrement : https://impact.zewo.ch/register/#reg_membership Plus d’informations sur les mesures d’impact et sur le ZIT : Français | Allemand | Anglais |